Representation Wins on QA, Not on ML
A paired-data study of three retrieval systems answering 13,800 specialty-medication adherence questions over 200 synthetic patients. The representation that wins natural-language QA is not the one that wins downstream prediction.
TL;DR. I generated paired FHIR and LLM-narrative representations of the same 200 synthetic patients, then ran three retrieval systems against 13,800 programmatically-verified adherence questions. Narrative RAG won QA at 40.6% exact-match, structured-aware RAG won retrieval but lost end-to-end on a constrained output budget, and structured FHIR features won the downstream adherence-prediction arm at AUC 0.997 vs 0.846. The format that wins question answering is not the format that wins prediction. Completed manuscript, May 2026. Zenodo deposit; arXiv submission pending.
A patient on a long-acting biologic gets a phone call from a case manager: "When is your next injection? Have you missed any doses in the last three months?" Behind that conversation sits a database. The same facts about that patient might live in two very different shapes inside a hospital system. One is a structured record built to a healthcare interoperability standard called FHIR, full of typed fields and references. The other is an English summary, often now generated by a large language model from the same underlying record. When a clinical AI assistant needs to answer the case manager's question, which version of the data should it read from?
That is the question this paper takes apart, with paired data and a hard set of metrics. Short answer: the format that wins question answering is not the format that wins downstream prediction. Different jobs want different shapes, and a system designer who picks one substrate for everything is leaving accuracy on the table.
Why this matters outside the lab
Specialty medications, biologics, long-acting injectables, cyclic chemotherapy regimens, account for roughly half of US prescription drug spending despite a small slice of total claims. Patient Support Programs (PSPs) wrap clinical infrastructure around these drugs to keep adherence on track. The questions PSP case managers ask every day map directly onto adherence indicators: Medication Possession Ratio (MPR), Proportion of Days Covered (PDC), persistence on therapy. None of these can be answered by a free-text search; they require multi-step temporal reasoning over the regimen.
At the same time, AI scribes from companies like Abridge, Nuance, and Ambience are now generating narrative summaries from millions of clinical encounters. So a typical health system in 2026 has both formats sitting on disk: structured FHIR resources from the EHR, and LLM-generated narratives from the scribe. A natural engineering instinct is to pick one and standardize. The data here suggests that instinct is wrong.
What was new about the setup
Earlier comparisons between structured and narrative clinical data had a measurement problem. They used independently authored sources, the FHIR record from one place, the discharge note from another, so any difference in performance reflected both the format and the information content simultaneously. You could not tell whether the structured record won because the format was better or because the structured record happened to carry more facts.
This study cuts the confound by generating both representations from the same source. Two hundred synthetic patients were rendered as FHIR R4B bundles, then a Llama 3.3-70B model converted each bundle into a narrative summary. An independent audit verified that all eight clinical entity classes were recoverable from the narratives, so information content is held constant across formats. Differences in accuracy now reflect format and retrieval strategy alone.
Three retrieval systems then answered the same 13,800 programmatically-verified questions:
- System A, Narrative RAG: a standard retrieval-augmented setup over the LLM narratives.
- System B, Structured Naive RAG: the same retrieval setup but over FHIR resources serialized to text.
- System C, Structured Aware RAG: System B plus three structural primitives: a typed resource filter, reference-chain traversal across the FHIR graph (MedicationRequest → Medication, Practitioner, Patient), and a temporal pre-filter on dates.
A fourth measurement extracted features from each representation and trained classifiers on a synthetic adherence prediction task.
What happened on the QA arm
The narrative system won.
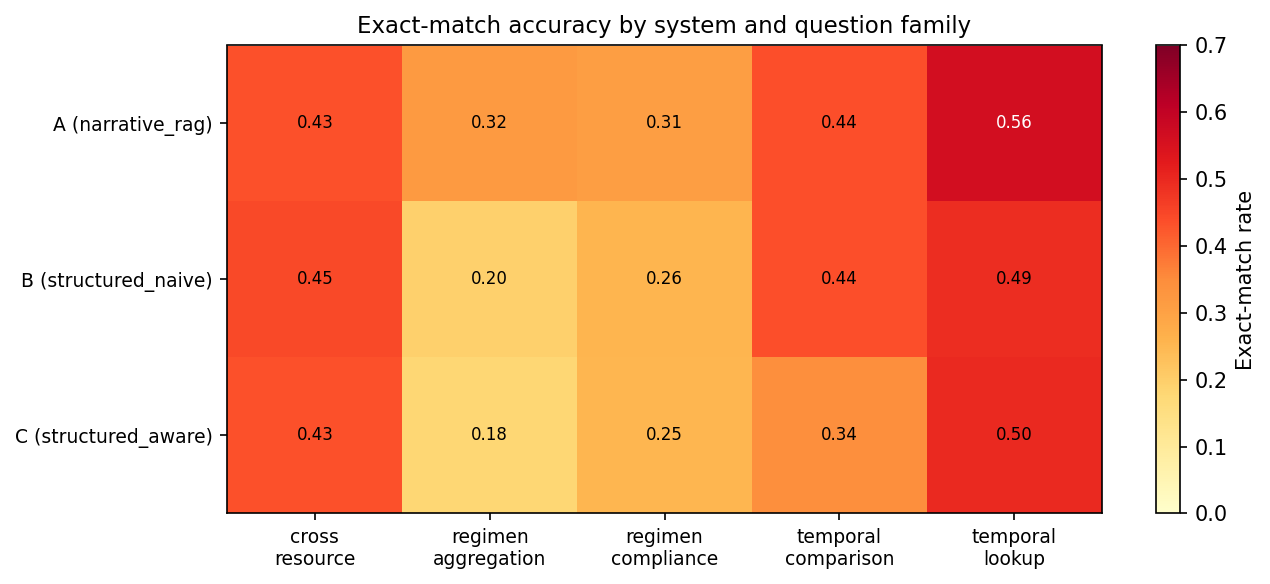
System A reached 40.6% exact-match accuracy. System B reached 35.3%. System C, despite its smarter retrieval, came in at 33.4%. All three pairwise differences are statistically significant. The narrative advantage was largest on dose-history aggregation (12.3 percentage points) and coverage-window reasoning (5.3 points), exactly the questions that demand step-by-step arithmetic over many records.
Exact-match QA accuracy · 13,800 questions
A complexity gradient ran underneath the headline numbers. On simple regimens (a single long-acting injectable on a fixed interval), the systems hit 40 to 54% accuracy. On multi-drug staggered schedules, every system collapsed to roughly 20%. Hard temporal arithmetic over multiple medications is not solved by any of these architectures yet.
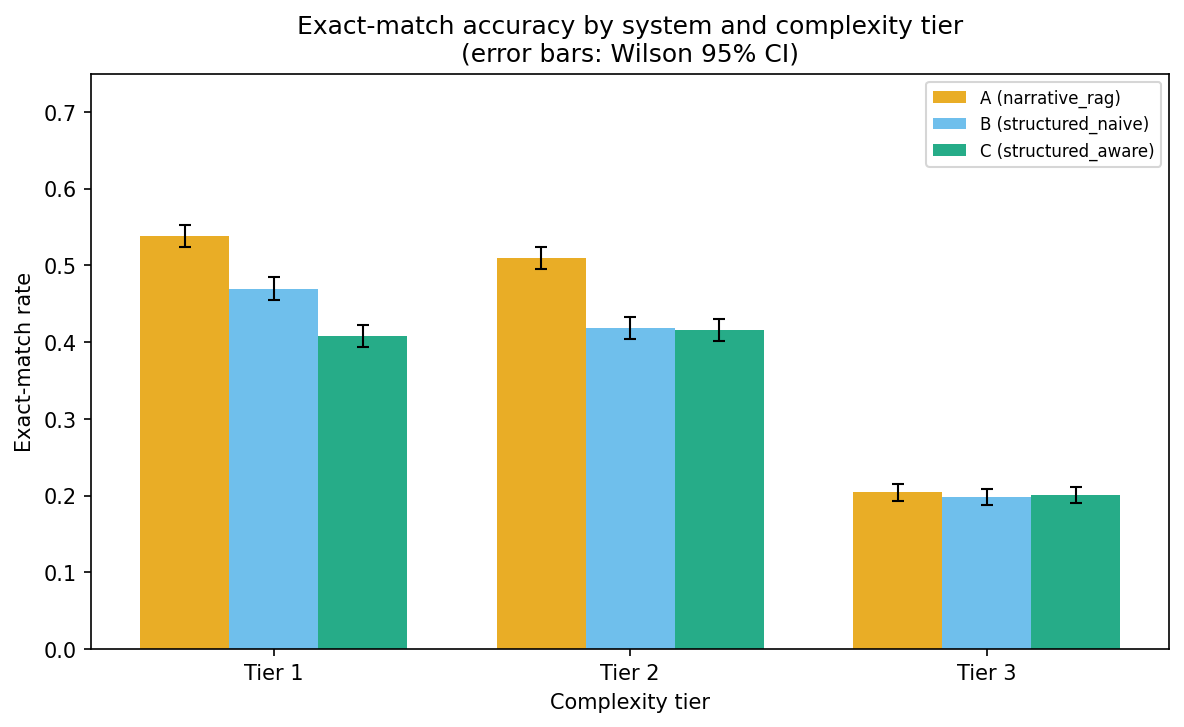
Why the structured systems lost (and it is not what you think)
A naive reading of the headline number says structured FHIR is worse than narrative for clinical QA. That reading is too quick. An error taxonomy on 50 failures per system told a sharper story.
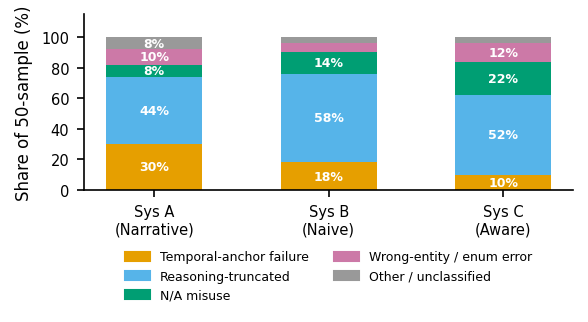
Reasoning truncation, the model running out of output tokens before arriving at a final answer, accounted for 44 to 58% of all failures. The rate was highest for System B (58%) and C (52%) because FHIR JSON is dense. Each retrieved chunk carries more raw text than a narrative paragraph (System B sent in 9× more tokens than System A on average), so the model has less room to think before its budget runs out. Set the output budget high enough and the gap should narrow.
Temporal-anchor failures told the opposite story. A reference date in a question (when is the next dose, as of date X?) does not appear in narrative chunks at all, so the model has to guess from context. FHIR resources carry explicit date fields like CarePlan.period.start and MedicationAdministration.effectiveDateTime. The result: 30% of System A's failures were temporal-anchor failures, against 10% for System C. This is a structural property that would persist regardless of token budget, and points toward a hybrid future where narrative chunks are stamped with reference-date metadata at indexing time.
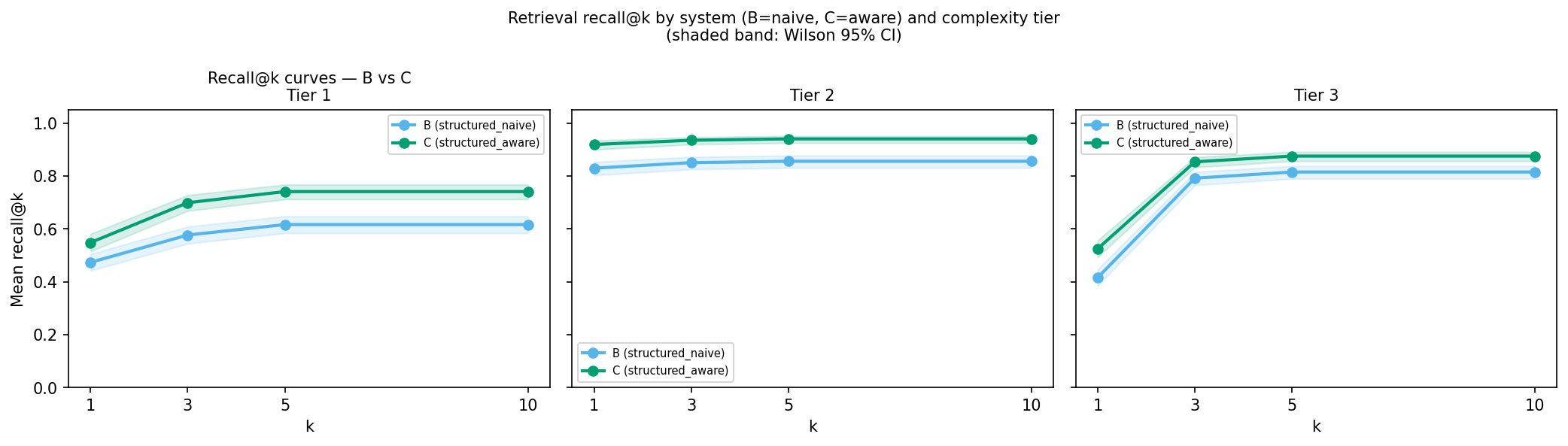
System C did succeed at one important thing: retrieval. Its resource-aware filtering pulled the right FHIR resource into the top-1 spot 66% of the time, against 57% for System B. The retrieval advantage just did not translate to an end-to-end accuracy advantage at this token budget.
The dissociation: the format that wins QA does not win prediction
The fourth arm of the study built three feature sets from the same patient cohort and trained a LightGBM classifier and a logistic regression on them to predict an adherence outcome.
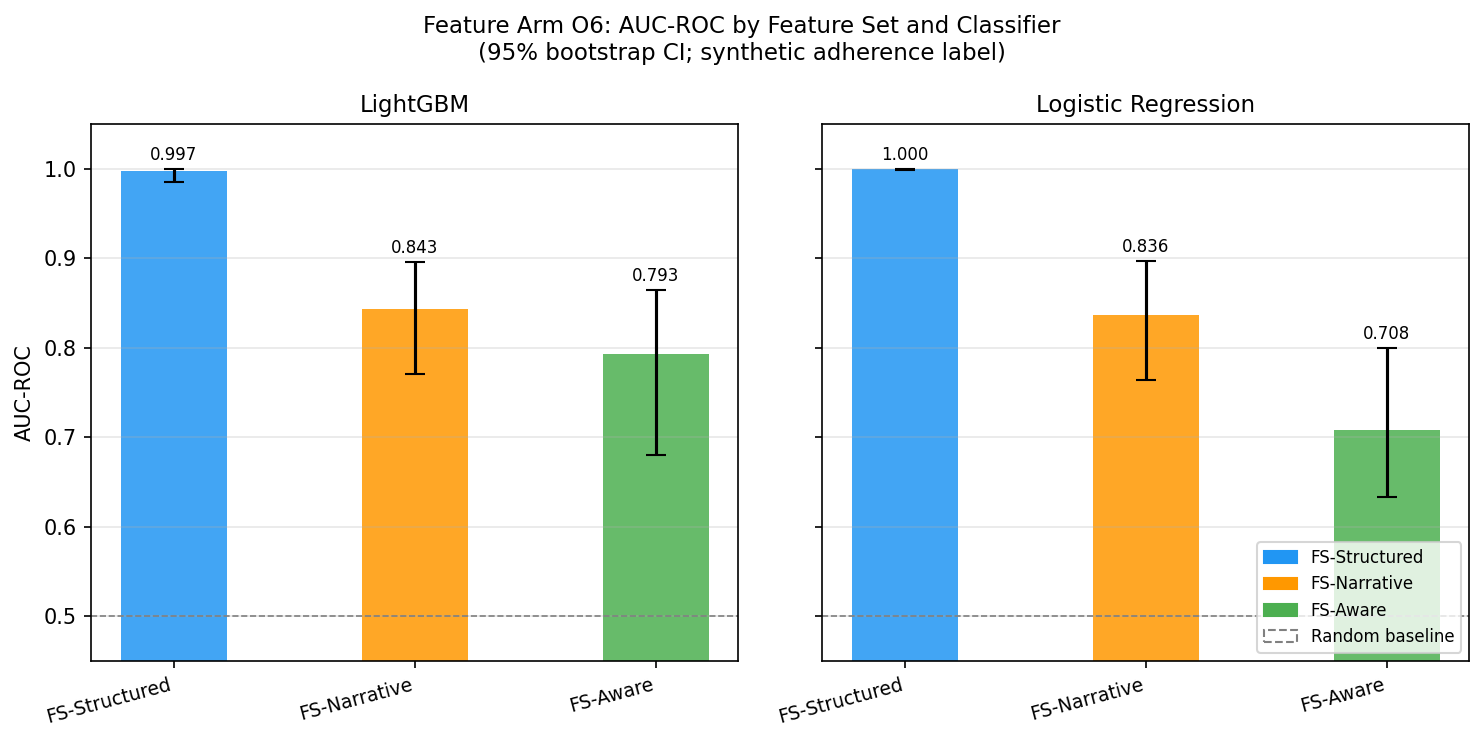
Structured FHIR features reached AUC 0.997. Narrative features reached 0.846. Retrieval-trace features reached 0.769. The structured representation that lost the QA comparison decisively won the prediction comparison.
Adherence-prediction AUC-ROC
The near-ceiling AUC on FS-Structured is partly a synthetic-data artifact: the labelling rule for the adherence outcome shares variables with the structured feature set (and the paper says so plainly). What is stable is the ordering: structured features encode the adherence signal more directly than narrative-derived or retrieval-trace features, and that ordering should hold under richer real-world labels too.
What designers should take away
If you build clinical RAG systems on specialty medications, the choice of representation should follow the downstream task rather than personal preference for one schema:
- For natural-language Q&A by case managers, narrative RAG is the lower-risk choice when the answer LLM has a constrained output budget. Compact context buys reasoning headroom inside a fixed token limit.
- For adherence risk stratification or any classifier where structured numerics matter, extract features from FHIR resources directly. Reusing the narrative representation costs you about 0.15 AUC points in this study, and the gap held across two classifier families.
- LLM-generated narratives are summaries. Treat them as such. The fidelity audit confirmed 100% entity recovery, but entity recovery does not guarantee that every temporal relation is preserved in a form the answer LLM can exploit during reasoning.
Honest limits
Everything in this paper is synthetic. Synthea's medication module is known to differ from real prescribing distributions, and the specialty regimen overlay covers only three complexity tiers (single LAI, cyclic, multi-drug). A 512-token output budget set for cost control is the dominant cause of error across all three systems and disproportionately penalizes the structured arms. A single answer LLM (Qwen3-32B) and a single embedding model (BGE-large) gate every result. The error taxonomy is single-rater. None of this invalidates the dissociation finding, but every absolute number deserves a sceptical look before being extrapolated to a production deployment.
The follow-up step is real de-identified PSP data after a research ethics board review, with the same paired-data design.
Why I wrote this paper
This study pulls together three things I care about: healthcare data interoperability, retrieval architectures for clinical AI, and the kind of empirical care that catches confounds before they bury a result. The paired-data setup was non-negotiable because every prior comparison I read had the same blind spot, comparing apples and oranges and reporting on apples. Constraining information content across representations was the single most useful methodological move I made.
If you build clinical AI systems, I would value your scepticism on the synthetic-label artifact in the prediction arm and on whether a hybrid retriever (narrative for Q&A, structured for prediction, both indexed off the same source) is worth the engineering cost.
- Manuscript: completed May 2026, arXiv submission pending.
- Manuscript and code: Zenodo · github.com/TJmetrichealth/FHIR_RAG_TEST
- License: Apache-2.0 (code) and CC-BY-4.0 (dataset, pending employer IP clearance)
- Get in touch: tirtheshjani@gmail.com