
“The cosmos is within us. We are made of star-stuff. We are a way for the universe to know itself..“
Carl Sagan
Motivation
Imagine standing under the night sky, gazing up at the stars twinkling above. Each star is a story, a beacon from afar that holds secrets about our universe’s past, present, and future. But how do we begin to understand these celestial narratives? This is where my first adventure into the realm of data science meets the infinite expanse of space—through a project dedicated to classifying stars, not with telescopes, but with the power of data, we embark on a journey to categorize the stars, aiming to deepen our understanding of their properties and behaviors. This blog post delves into the project’s motivations, methodologies, findings, and the broader implications of marrying data science with astronomy.

The motivation behind this project was to leverage the power of machine learning to contribute to our understanding of the universe, making sense of the data that the cosmos offers. Utilizing a comprehensive dataset that encapsulates various stellar parameters such as temperature, luminosity, radius, and more, the goal was to predict the classification of stars into one of several types, each reflecting unique stages in stellar evolution or distinct properties.
This endeavor was not merely an academic exercise but a practical exploration into how data science techniques can be applied to real-world astronomical data. The dataset, sourced from reputable astronomical studies, included observations of stars across different spectral classes, sizes, and luminosities, providing a rich tapestry of information for analysis. By applying classification algorithms, the project sought to identify patterns and relationships within the data, enabling the categorization of stars in a way that aligns with our current astronomical understanding.
In the following sections, we’ll delve into the methodology employed to achieve this classification, discuss the results and their implications, and consider how this project not only advances our knowledge of the stars but also demonstrates the potential of data science in enhancing our comprehension of the universe.
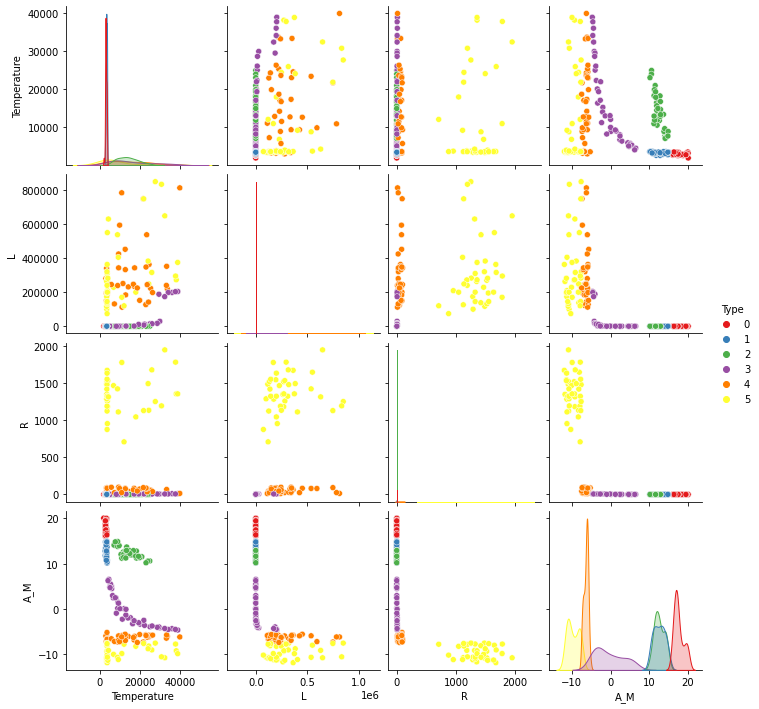
The Data
The dataset includes the following variables for each star:
Temperature (in Kelvin)
Luminosity (L, in L/Lo)
Absolute Magnitude (AM, in Mv)
Color (General Color of Spectrum)
Spectral Class (O, B, A, F, G, K, M)
Type (categorized from 0 to 5):
0: Red Dwarf
1: Brown Dwarf
2: White Dwarf
3: Main Sequence
4: Super Giants
5: Hyper Giants
Methodology
The methodology adopted in this project was a systematic approach that combined data preprocessing, model selection, and rigorous validation to classify star types accurately. Here’s how the process unfolded:
Data Preprocessing
The first step involved cleaning and preparing the astronomical data for analysis. This phase was crucial, as the quality of data directly impacts the model’s performance. We addressed missing values, normalized the data to ensure consistency across different scales, and encoded categorical variables when necessary. This preprocessing not only streamlined the dataset but also enhanced the model’s ability to learn from the data effectively.
Model Selection
Choosing the right machine learning model was pivotal to the project’s success. Given the nature of the classification task, we experimented with several algorithms renowned for their classification capabilities, including Decision Trees, Random Forest, Support Vector Machines (SVM), and Neural Networks. Each model was evaluated for its suitability based on the dataset’s characteristics and the complexity of the classification task at hand.
Training and Validation
With the models selected, the next step was training them using a portion of the dataset. This process involved feeding the models with data for which the classifications were already known, allowing them to learn and make predictions. To ensure the models’ accuracy and avoid overfitting, we employed cross-validation techniques. This involved dividing the dataset into a training set and a validation set, where the latter was used to test the models’ predictive power and adjust parameters accordingly.
Model Evaluation
The final step in the methodology was evaluating each model’s performance using metrics such as accuracy, precision, recall, and F1 score. These metrics provided insights into how well each model performed in classifying the stars, guiding the selection of the most effective model for the task.
Results and Analysis
The culmination of meticulous data preprocessing, careful model selection, and rigorous validation was a comprehensive understanding of the models’ abilities to classify star types accurately. The project yielded several key findings:
- Model Performance: Among the various models tested, the Random Forest algorithm emerged as the standout, demonstrating superior performance in terms of accuracy, precision, and recall. Its ability to handle the complexity and nuances of the dataset was evident, making it the preferred choice for this classification task.
- Feature Importance: Analysis revealed that certain features played a more significant role in determining star types. Temperature, luminosity, and radius were among the most influential, aligning with astronomical principles that these characteristics are pivotal in defining a star’s classification.
- Classification Insights: The project not only achieved high accuracy in classification but also provided insights into the relationships between different stellar characteristics and their types. For instance, it highlighted how certain combinations of features are indicative of specific star types, offering a data-driven approach to understanding stellar classification.
As we stand at the confluence of data science and astronomy, projects like these not only contribute to our scientific knowledge but also inspire a sense of wonder and possibility.
