This project was an ambitious attempt to build a Deep Generative Stellar Spectra Model using Gradient Origin Networks (GONs), a novel machine learning architecture. The goal was to harness public data from premier astronomical surveys, GALAH and APOGEE, to create a unified model of stellar fingerprints.
While the project’s original scope proved too ambitious to complete, the journey became an invaluable lesson in the practical challenges of applied scientific machine learning. The process of collecting, filtering, and attempting to model data for approximately 30,000 stars provided foundational expertise in spectroscopic data analysis, Python-based data pipelines, and the critical role that “failed” experiments play in driving scientific insight.
Key Learnings & Outcomes:
Developed a robust data processing pipeline in Python to ingest and clean complex stellar spectra from multiple astronomical surveys.
Gained deep domain knowledge in stellar spectroscopy, including the strengths and limitations of the GALAH (optical) and APOGEE (infrared) datasets.
Acquired hands-on experience with the technical challenges of training advanced generative models on large-scale scientific data.
The Scientific Vision: Galactic Archaeology with Machine Learning
Stellar spectroscopy is a cornerstone of modern astronomy. The light from a star acts as a cosmic fingerprint, with its absorption lines revealing chemical composition, temperature, and motion. Large-scale surveys like GALAH and APOGEE are capturing millions of these fingerprints, enabling the field of galactic archaeology—reconstructing the formation and evolution of our Milky Way.
While traditional physics-based analysis is computationally expensive, and most machine learning models are discriminative (mapping spectra to parameters), this project explored a generative approach. A successful generative model could:
Synthesize realistic new stellar spectra.
Handle missing or incomplete data.
Improve anomaly detection for discovering rare stellar objects.
The chosen architecture, Gradient Origin Networks (GONs), offered a path to a more efficient model, requiring 50% fewer parameters than traditional autoencoders. The plan was to train a GON on both GALAH and APOGEE data to create a shared latent space for optical and infrared spectra.
The Data: GALAH and APOGEE Surveys
A major challenge was harmonizing data from two distinct but complementary surveys:
| Survey | Wavelength | Resolution (R) | Primary Targets & Strengths |
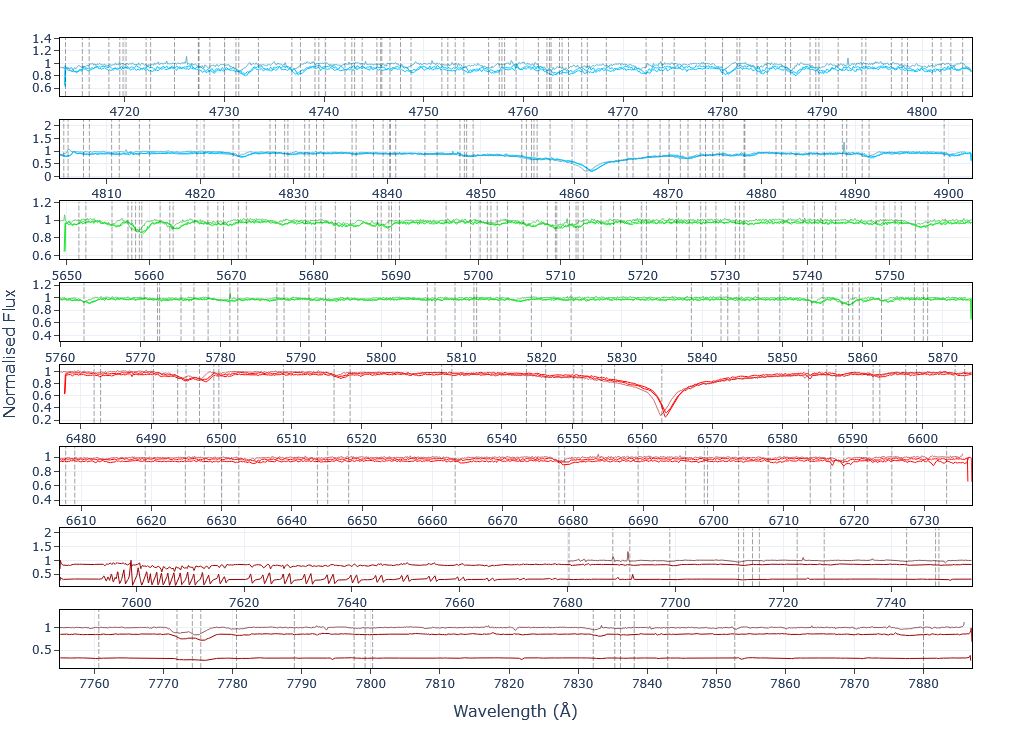
| GALAH | Optical (471-789 nm) | ~28,000 | Dwarf stars in the local solar neighborhood. Excels at measuring light elements like lithium and carbon. |
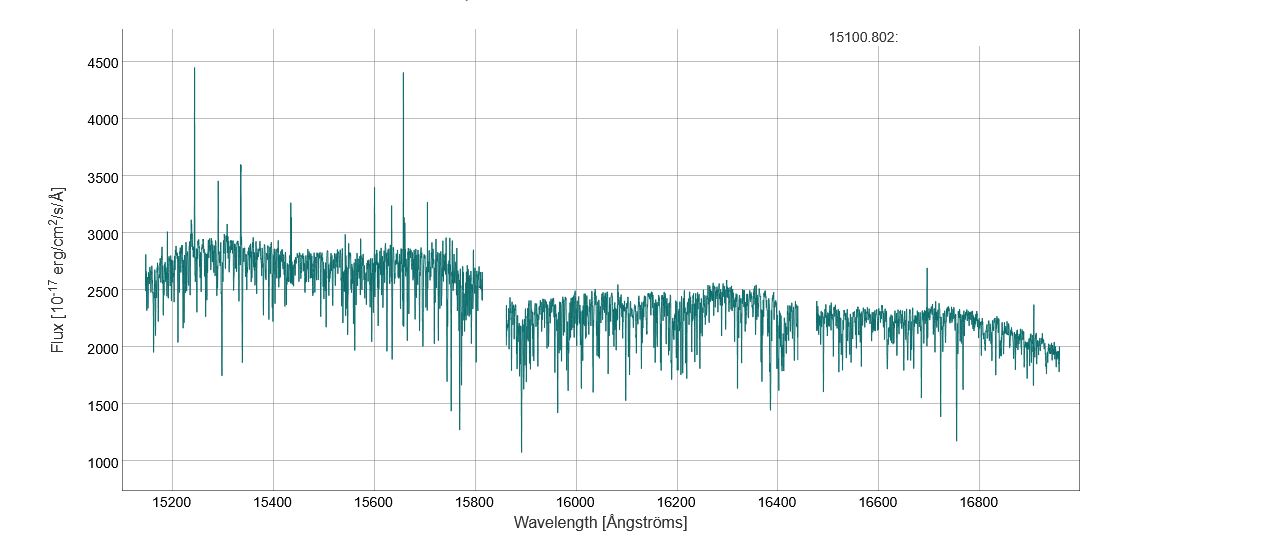
| APOGEE | Near-Infrared (1.5-1.7 μm) | ~22,500 | Red giant stars. Penetrates cosmic dust to observe the galactic bulge and inner disk. |
Cross-calibrating these surveys is a significant hurdle due to differences in wavelength, resolution, and analysis pipelines. This project required a deep dive into the nuances of each dataset to create a cohesive foundation for the machine learning model.
The Challenge & Conclusion: Lessons from the Final Frontier
The primary obstacle was the sheer complexity of the task. After six months of intensive work, it became clear that the project’s scope—from data harmonization to training a novel deep learning architecture—was more suited for a multi-person research team than a solo endeavor.
However, this “failure” to reach the final goal was a profound success in learning. This project solidified my understanding of the end-to-end machine learning lifecycle in a complex scientific domain and underscored a core tenet of research: the most valuable insights often come from pushing boundaries, even if you don’t reach your intended destination. The foundational expertise I built continues to inform my data-driven approach to every problem I solve today.

The Theoretical Challenge: Applying GONs to Spectroscopy
When this project began, generative models were rapidly evolving. Variational Autoencoders (VAEs), Normalizing Flows, and Generative Adversarial Networks (GANs) had all shown promise, but Gradient Origin Networks (GONs) presented an intriguing, parameter-efficient alternative. Introduced by Bond-Taylor and Willcocks, GONs eliminate the need for an encoder network by using the gradient of the log-likelihood as the latent representation. While mathematically elegant, I quickly discovered a critical gap: GONs had never been applied to astronomical data. Adapting them required tackling several fundamental challenges:
Physics-Informed Constraints: Unlike natural images, stellar spectra are governed by the laws of radiative transfer. A successful model must respect these physical relationships.
Multi-Scale Features: The model needed to simultaneously learn the broad continuum shape of a spectrum and the narrow, high-frequency absorption lines.
Complex Noise Properties: Real-world astronomical observations have intricate noise characteristics that are difficult to model.
The core challenge was clear: how to integrate the complex physics of stellar atmospheres into a novel deep-learning architecture that was designed for a completely different data domain

Technical Deep Dive: Navigating the Python Astronomy Ecosystem
The theoretical hurdles were matched by practical implementation challenges within the Python scientific computing environment. Processing massive astronomical datasets efficiently is a specialized skill that goes far beyond typical data science workflows.
Wrestling with Astropy and FITS Files
The Astropy library is the cornerstone of Python astronomy, but it has significant complexities. I discovered that FITS files use memory mapping by default, creating persistent file handles. Processing thousands of spectra sequentially led to resource exhaustion as these memory-mapped objects accumulated. The solution was not just closing the file, but performing explicit garbage collection in the processing pipeline:
# Essential for releasing memory-mapped FITS file handles in a loop
del hdul[0].data
gc.collect()
FITS files also presented numerous edge cases, from multi-extension files that mixed data types to compressed files that traded storage space for slower access speeds.
The Nuances of specutils and NumPy
The specutils library, while powerful for spectral analysis, required careful navigation of its evolving API. A major version update changed how flux arrays were handled, breaking code. Furthermore, seemingly simple operations like arithmetic between two spectra required explicit resampling if their wavelength grids didn’t match.
Working with NumPy on datasets that exceeded available RAM revealed the hidden dangers of its broadcasting feature, which can create enormous temporary arrays. Mastering the distinction between NumPy views and copies became critical for memory optimization.
Performance, Parallelism, and the GIL
For large catalogs, naive O(N²) algorithms for cross-matching were prohibitively slow. This forced me to learn systematic code profiling and efficient parallel processing strategies. However, Python’s Global Interpreter Lock (GIL) limits the effectiveness of threading for CPU-bound tasks, requiring a move to multiprocessing, which added its own layer of complexity to debugging and error handling.
{kind=link}
{kind=link}
Beyond the Code: The Realities of Early-Career Research
This project was a humbling lesson in the vast gap between theoretical knowledge and practical implementation. The biggest challenges weren’t always in the code, but in the process itself.
Documentation Gaps: Official tutorials often assumed background knowledge I lacked, while online examples frequently used outdated syntax.
Debugging Nightmares: Traditional debugging methods fail when dealing with high-dimensional latent spaces, subtle numerical precision issues, and training instabilities that only appear after hours of computation.
Psychological Pressure: The intense pressure on early-career researchers to show rapid progress clashes with the reality of complex projects, which can show little visible progress for months. This fueled a strong sense of imposter syndrome.
Project Management: Learning to balance perfectionism with practical constraints and manage a project with a nonlinear progress curve became a crucial, hard-won skill.
Recognizing the Summit: When Complexity Exceeds Capability
After months, I had successfully built a high-quality dataset of ~30,000 stars from the GALAH and APOGEE surveys. However, the core task of implementing a physics-informed GON for spectroscopy proved to be beyond the scope of a solo project for someone at my skill level. It required deep, concurrent expertise in:
Deep Learning Architecture Design
Astronomical Data Analysis
High-Performance Computing
Software Engineering
The decision to step back was not an admission of failure, but a strategic recognition of my current limitations and a commitment to building the necessary skills for the future.
From Setback to Strategy: Building a Foundation for the Future
Research from Northwestern University shows that early-career scientists who experience setbacks often outperform their peers in the long term. My “failed” project perfectly exemplifies this pattern. The struggle provided an invaluable education that now serves as a foundation for all my subsequent work.
Lessons in Project Management and Strategy
Incremental Development: Start with simpler models (like a standard VAE) to build expertise before tackling novel architectures.
Collaborative Frameworks: Modern scientific machine learning often requires interdisciplinary teams. Solo projects have inherent limitations.
Infrastructure Planning: Assess computational needs before starting development to set realistic goals and timelines.
Translating Experience into Future Success
The key to maximizing the value of a challenging project is to strategically present the learning experience. This project provided a wealth of transferable skills:
Technical Competencies: Advanced Python for large-scale data processing, deep familiarity with astronomical surveys, and systematic debugging and optimization.
Project Management Skills: Realistic scope estimation, resource planning, and strategic decision-making.
Professional Storytelling: The ability to frame a challenging experience as a compelling narrative of growth, resilience, and learning.
Conclusion: Struggle is Not a Bug, It’s a Feature 💡
This project reinforced a fundamental truth: discovery is iterative. The scientific method advances through both positive and negative results. For early-career researchers, remember that your “failed” projects may well become your most valuable assets. The skills, resilience, and deep understanding that emerge from wrestling with complex problems are the true markers of professional growth.
References
- https://arxiv.org/pdf/2007.02798
- https://www.sdss4.org/dr17/irspec/
- https://www.galah-survey.org/dr4/overview/