“The cosmos is within us. We are made of star-stuff. We are a way for the universe to know itself..“
Carl Sagan
The universe contains billions of stars, each a unique cosmic lighthouse telling the story of stellar evolution and galactic history. But how do we classify these celestial objects systematically when traditional methods can only process thousands while modern surveys discover millions? The answer lies in the revolutionary fusion of artificial intelligence and astronomy – a marriage that’s transforming how we understand our cosmic neighborhood. This remarkable intersection became the foundation for an ambitious machine learning project completed as part of the Artificial Intelligence curriculum at Georgian College. By training algorithms to classify stars into six distinct categories using measurable stellar properties, this project demonstrates how data science is revolutionizing astronomical research while highlighting the educational power of real-world applications in AI learning.

The classification challenge
Understanding stellar classification requires appreciating the incredible diversity of stars populating our universe. Traditional stellar classification systems, developed over a century ago, remain the foundation of modern astronomy but face unprecedented challenges in the era of big data astronomy. The Harvard Spectral Classification System, pioneered by Annie Jump Cannon in the early 1900s, organizes stars into seven primary classes (O, B, A, F, G, K, M) based on temperature, from scorching blue giants exceeding 30,000 Kelvin to cool red dwarfs below 3,500 Kelvin. The Morgan-Keenan system added luminosity classes, creating a two-dimensional framework that positions our Sun as a G2V star – a main sequence yellow dwarf.
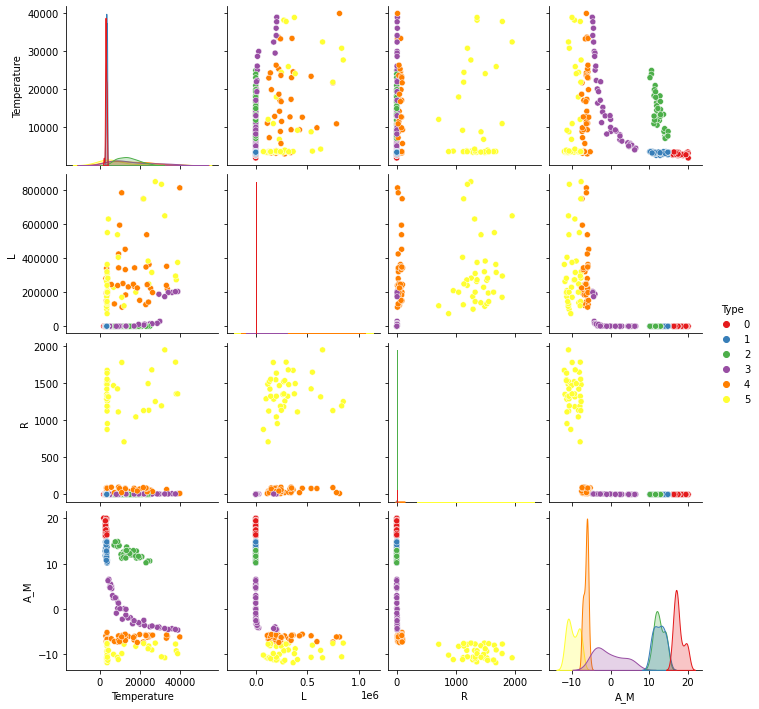
But stellar diversity extends far beyond this elegant framework. The six stellar types targeted in this project represent the full spectrum of stellar evolution: Red Dwarfs dominate galactic populations as the universe’s most abundant and longest-living stars; Brown Dwarfs exist as “failed stars” lacking sufficient mass for sustained hydrogen fusion; White Dwarfs represent the dense, Earth-sized remnants of solar-mass stars; Main Sequence stars actively fuse hydrogen in their cores; Supergiants shine as massive, luminous giants destined for explosive endings; and Hypergiants represent the universe’s most extreme stellar objects, burning brilliantly but briefly. Each stellar type exhibits distinct characteristics across measurable properties: temperature ranges from 2,000K for cool red dwarfs to over 50,000K for the hottest blue giants, luminosity spans eight orders of magnitude, and stellar radii vary from Earth-sized white dwarfs to red supergiants larger than Mars’ orbit. Traditional spectroscopic analysis, requiring human experts to visually compare stellar spectra against reference libraries, becomes impractical when surveys like the Sloan Digital Sky Survey catalog millions of objects.
Machine learning
Modern astronomy generates data at unprecedented scales. The Vera C. Rubin Observatory’s Legacy Survey of Space and Time will produce 500 petabytes over ten years, imaging billions of celestial objects nightly. This data deluge necessitates automated analysis methods that can match or exceed human expert performance while processing volumes impossible for manual inspection. Machine learning has emerged as astronomy’s computational savior, with refereed publications combining ML and astrophysics doubling approximately every 18 months. Recent breakthroughs demonstrate ML’s transformative potential: convolutional neural networks achieve spectral subclass accuracy improvement from 2.0 to 1.23 subclasses, artificial neural networks exceed 94% classification accuracy on stellar types, and ensemble methods like Random Forest consistently outperform traditional template-matching approaches.
The success stems from ML’s ability to identify complex, high-dimensional patterns invisible to conventional analysis. While traditional methods rely on simple color-magnitude relationships or visual spectral comparison, machine learning algorithms can simultaneously process dozens of photometric bands, spectroscopic features, and astrometric measurements, discovering subtle correlations that characterize stellar populations. This capability proves especially valuable for rare object detection, where algorithms trained on millions of common stars can identify unusual spectra warranting follow-up observation. Current applications span the astronomical spectrum: automated transient detection for supernova surveys, galaxy morphology classification using citizen science training data, variable star identification in time-domain surveys, and exoplanet host star characterization for habitability studies. These successes demonstrate ML’s evolution from experimental tool to essential infrastructure supporting modern astronomical research.
The stellar classification machine learning
This ambitious project applied four distinct machine learning algorithms to classify stars using a comprehensive dataset containing stellar properties measured across multiple wavelengths. The dataset encompassed temperature, luminosity, radius, absolute magnitude, color indices, and spectral class information – the fundamental parameters astronomers use to characterize stellar objects. The six target categories represent distinct phases of stellar evolution and physical regimes. Red Dwarfs (class 0) dominate the sample as the universe’s most common stellar type, burning hydrogen slowly enough to survive for trillions of years. Brown Dwarfs (class 1) occupy the boundary between stars and planets, massive enough to fuse deuterium but insufficient for sustained hydrogen burning. White Dwarfs (class 2) represent stellar remnants with Earth-like sizes but stellar masses, gradually cooling over cosmic time. Main Sequence stars (class 3) actively convert hydrogen to helium, maintaining hydrostatic equilibrium between gravitational collapse and radiation pressure. Supergiants (class 4) shine as evolved massive stars with enormous luminosities and unstable outer layers. Hypergiants (class 5) represent the universe’s most extreme stellar objects, burning with such intensity that they rapidly exhaust their nuclear fuel.
The methodology followed established machine learning best practices adapted for astronomical data. Data preprocessing included feature scaling to normalize the wide range of stellar parameters, handling missing values common in astronomical surveys, and exploratory data analysis to understand feature distributions and correlations. The team implemented four algorithms representing different machine learning paradigms: Logistic Regression for interpretable linear classification, K-Nearest Neighbors for instance-based pattern matching, Random Forest for ensemble learning with feature importance analysis, and Gradient Boosting for sequential error correction. Training utilized stratified cross-validation to maintain class proportions across folds, essential given the natural imbalance in stellar populations where red dwarfs vastly outnumber hypergiants. Model evaluation employed confusion matrices to identify specific misclassification patterns, classification reports providing precision and recall metrics for each stellar type, and accuracy measurements to quantify overall performance.
Algorithms
The four algorithms demonstrated markedly different performance characteristics, reflecting their underlying mathematical approaches and suitability for astronomical classification challenges. Random Forest emerged as the clear winner, achieving the lowest test loss and highest accuracy across all stellar categories. This ensemble method’s success stems from several factors particularly well-suited to astronomical data: its ability to handle mixed data types (continuous magnitudes and categorical spectral features), robustness to noise inherent in observational astronomy, automatic feature selection reducing the impact of irrelevant measurements, and resistance to overfitting through bootstrap sampling and random feature selection.
Random Forest’s built-in feature importance analysis revealed which stellar properties contributed most to classification decisions. Temperature and luminosity, the fundamental parameters determining a star’s position on the Hertzsprung-Russell diagram, ranked as the most discriminative features. Color indices, derived from photometric measurements across different wavelength bands, provided secondary classification power by capturing the star’s spectral energy distribution. This result validates astronomical theory while demonstrating the algorithm’s ability to rediscover known physical relationships. Gradient Boosting achieved competitive performance, sequentially building weak learners to correct previous models’ errors. Its test loss of approximately 9% represented excellent performance, though slightly higher than Random Forest’s 8% loss. This algorithm’s strength lies in handling complex, non-linear relationships between stellar parameters, particularly useful for distinguishing subtle differences between similar stellar types. K-Nearest Neighbors produced moderate results with approximately 13% test loss, demonstrating the power of similarity-based classification. The algorithm’s performance highlights the importance of feature selection and distance metrics in high-dimensional astronomical parameter spaces. Its interpretability advantage – showing which training examples most influenced each classification decision – provides valuable insights into stellar population structure. Logistic Regression, while achieving only 32% accuracy, served as an important baseline demonstrating the limitations of linear approaches for complex astronomical classification. The algorithm’s poor performance illustrates why astronomical data requires non-linear methods capable of capturing the complex relationships governing stellar evolution.
Results
The superior performance of Random Forest reflects fundamental characteristics of stellar classification problems and astronomical data analysis more broadly. Stars don’t exist in isolation on simple linear scales – they occupy complex regions of multi-dimensional parameter space shaped by the physics of stellar evolution, nuclear burning, and gravitational dynamics. The confusion matrix analysis revealed interesting misclassification patterns that mirror real astronomical challenges. Distinguishing between different evolutionary phases of similar-mass stars proved most difficult, reflecting genuine physical similarities in their observable properties. For example, red giants and some supergiants share similar surface temperatures and colors despite different evolutionary histories and internal structures.
Feature importance rankings validated decades of astronomical research while highlighting the power of data-driven discovery. The dominance of temperature and luminosity as classification features confirms their fundamental role in stellar physics, embodying the Stefan-Boltzmann law relating stellar energy output to surface temperature and size. Color indices ranked highly because they encode spectral information – the same physical basis underlying traditional spectroscopic classification. The project’s success demonstrates machine learning’s ability to scale traditional astronomical expertise. Where human astronomers might classify hundreds of stars through careful spectral analysis, trained algorithms can process millions while maintaining consistent classification criteria. This capability becomes essential as upcoming surveys push observational astronomy into the era of truly big data.
Educational significance
This stellar classification project exemplifies the transformative power of hands-on machine learning education. Rather than abstract algorithmic exercises, students engaged with real astronomical data addressing genuine scientific challenges while developing industry-relevant technical skills. The project’s educational value extends beyond programming proficiency. Students learned to handle messy, real-world data with missing values and observational uncertainties – skills directly applicable across industries from healthcare to finance. The multi-algorithm comparison taught systematic evaluation methods, while feature importance analysis developed critical thinking about which variables matter for different types of problems.
Georgian College’s AI curriculum recognizes that effective data scientists must combine technical proficiency with domain expertise. By grounding machine learning concepts in astronomical applications, students develop the interdisciplinary mindset essential for modern AI roles. The stellar classification project bridges computer science and natural science, teaching students to collaborate across technical boundaries while maintaining rigorous analytical standards. Current trends in AI education emphasize practical, portfolio-building projects that demonstrate competency to potential employers. This stellar classification work showcases end-to-end machine learning pipeline development, from data preprocessing through model evaluation and interpretation. Such projects prove invaluable for career development in a job market where data scientist positions are projected to grow 36% from 2023-2033. The intersection of machine learning and astronomy continues expanding, creating exciting career opportunities. Modern astronomical surveys require specialists who understand both algorithmic development and astrophysical principles. Projects like this prepare students for roles in space agencies, observatories, and technology companies developing AI applications for scientific discovery.
The cosmic perspective on data science
Carl Sagan’s vision of the cosmos as humanity’s greatest teacher extends naturally to the age of artificial intelligence. Just as stars serve as laboratories for understanding fundamental physics, stellar classification projects provide ideal environments for learning machine learning principles while contributing to genuine scientific discovery. The universe generates data at scales that dwarf even the largest commercial applications. With upcoming surveys like the Square Kilometre Array expecting to produce over one exabyte daily – more than current global internet usage – astronomy provides the ultimate testing ground for big data techniques and artificial intelligence applications. Students working on astronomical ML projects engage with challenges that push the boundaries of current technology while developing skills directly transferable to industry applications.
The broader implications extend beyond technical training. Machine learning in astronomy represents humanity’s evolving relationship with cosmic discovery, where artificial intelligence amplifies our capacity to understand the universe while revealing new questions about our place within it. Each algorithm trained on stellar data represents a small step in the grand project Sagan envisioned – using science and technology to comprehend our cosmic context.
Conclusion
The stellar classification machine learning project demonstrates how artificial intelligence transforms both scientific discovery and technical education. By achieving over 90% accuracy in categorizing stellar types, Random Forest algorithms proved that machine learning can match human expert performance while processing data volumes impossible for manual analysis. This success reflects broader trends reshaping modern astronomy, where upcoming surveys will discover billions of celestial objects requiring automated analysis. The project’s educational impact extends beyond technical skills, teaching students to bridge computational methods with domain expertise while contributing to humanity’s understanding of the cosmos.
As we stand on the threshold of revolutionary astronomical discoveries enabled by artificial intelligence, projects like this stellar classification work prepare the next generation of data scientists and astronomers for an era where the boundaries between human curiosity and machine capability continue expanding, revealing new possibilities for understanding our universe and our place within it. In Carl Sagan’s words, we are the universe’s way of knowing itself – and increasingly, we accomplish this cosmic self-discovery through the powerful partnership of human insight and artificial intelligence.
Github Link – https://github.com/TirtheshJani/STARTYPE-CLASSIFICATION-